Lab 4.2: Funcionalidade Datapool
O Datapool é uma funcionalidade da BotCity que permite o processamento de um conjunto de itens em larga escala. Com ele é possível gerenciar os itens de forma individual por um ou mais processos de automação.
Criar um Datapool
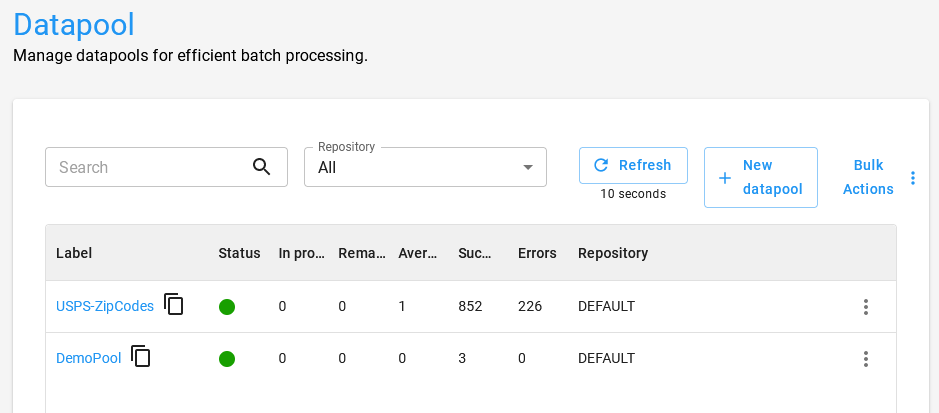
Para esse projeto, navegue no Orquestrador BotCity no menu lateral Datapool, clique em + Novo Datapool e preencha os formulários:
1. Informações Básicas
- Label: O identificador único que será utilizado para acessar o Datapool.
- Nome: O nome amigavel do Datapool.
- Repositório: O repositório onde o Datapool será armazenado.
- Status: O status do Datapool, que pode ser
AtivoouInativo. - Politica de consumo: Você pode escolher entre duas políticas de consumo.
- FIFO: O primeiro item a ser adicionado ao Datapool também será o primeiro item a ser processado.
- LIFO: O último item a ser adicionado ao Datapool será o primeiro item a ser processado.
2. Configurações de Processamento
Nessa etapa, você deve configurar o comportamento do Datapool durante o processamento dos itens.
- Tempo de processamento: permite definir qual o tempo esperado (em minutos) para que um item do Datapool seja processado em condições normais.
- Auto-retry: permite que um item seja reprocessado automaticamente em caso de erro do tipo
SYSTEM. - Abortar em caso de erro: faz com o que o Datapool fique inativo e não seja mais consumido em caso de erros consecutivos do tipo
SYSTEM. - Gatilhos de disparo de tarefas: define se o Datapool criado também vai ser responsável por disparar novas tarefas:
- Nunca disparar nova tarefa: O Datapool nunca será responsável por disparar tarefas de um processo de automação.
- Disparar nova tarefa a cada item adicionado: Sempre que um novo item for adicionado ao Datapool, uma nova tarefa de um determinado processo de automação será criada.
- Disparar nova tarefa apenas se não houver tarefas pendentes: Sempre que um novo item for adicionado, o Datapool irá disparar uma nova tarefa de um processo de automação somente se não existirem tarefas desse processo sendo executadas ou pendentes.
- Automação: O processo de automação que será utilizado pelo Datapool para disparar novas tarefas, se algum gatilho estiver sendo utilizado.

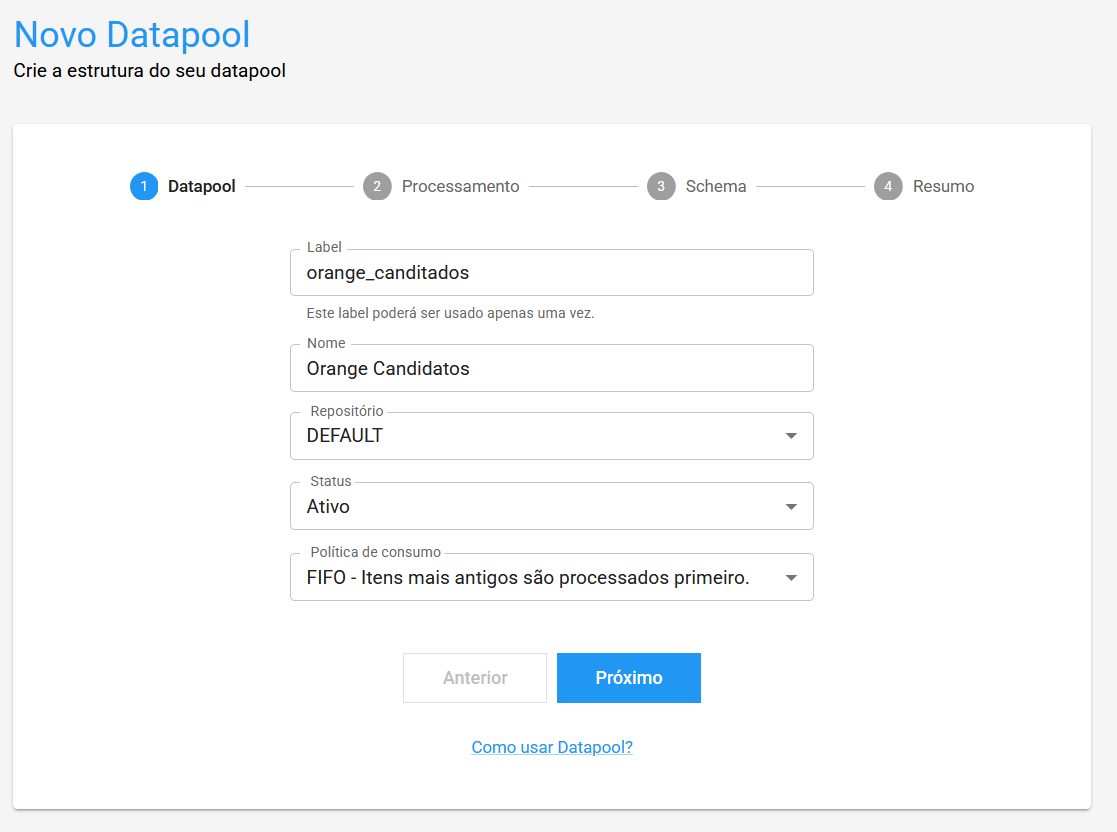
3. Definir o Esquema
Pode ser definida a estrutura dos itens que serão adicionados ao Datapool, ou seja, quais campos irão compor cada item.
- Label: O identificador único que será utilizado para acessar esse campo.
- Tipo: O tipo esperado para o valor desse campo (TEXT, INTEGER, DOUBLE).
- ID único: Se marcado, o campo irá representar uma "chave única" para o item, ou seja, não será permitido adicionar itens duplicados que tenham o mesmo valor para esse campo em específico.
- Exibir valor: Se marcado, o valor desse campo será exibido na lista de itens do Datapool, servindo como um identificador visual para os itens em questão.
Para esse treinamento usaremos as seguintes colunas, todas com o tipo TEXT:
full_name
vacancy
email
contact_number
keywords
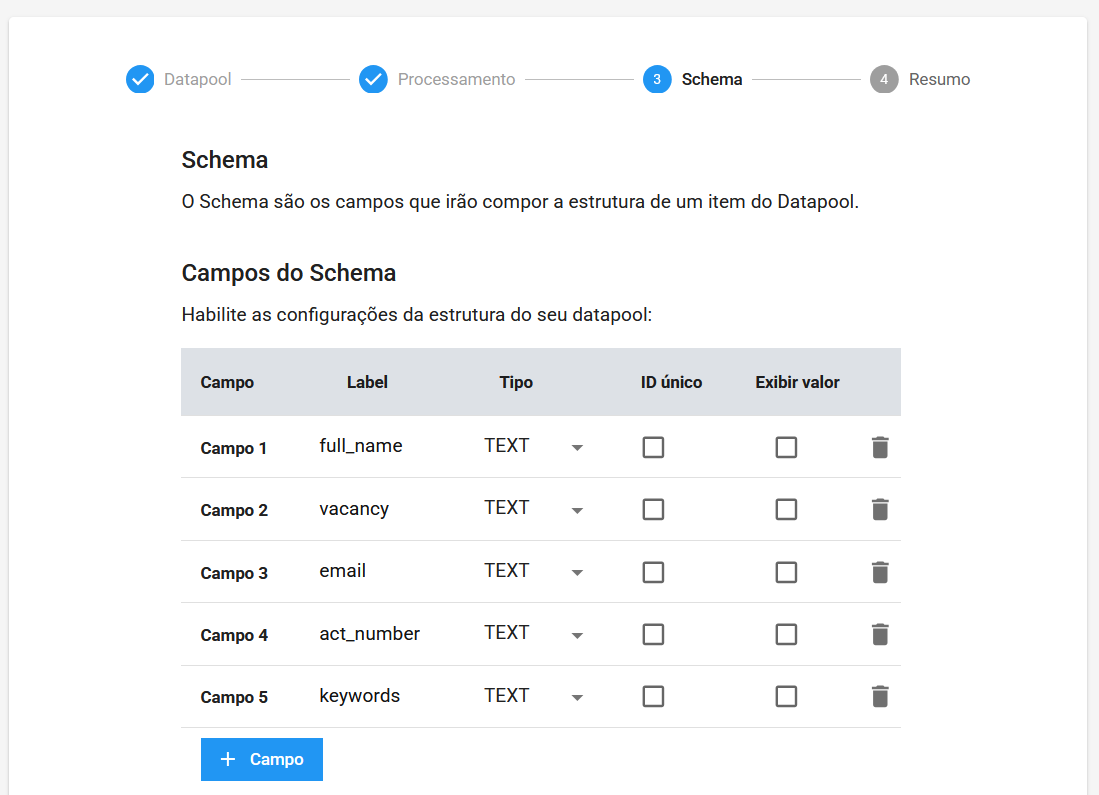
4. Resumo
Ao final, revise as informações e clique em Confirmar.
Nota
Para entender cada um dos campos, veja a documentação do Datapool.
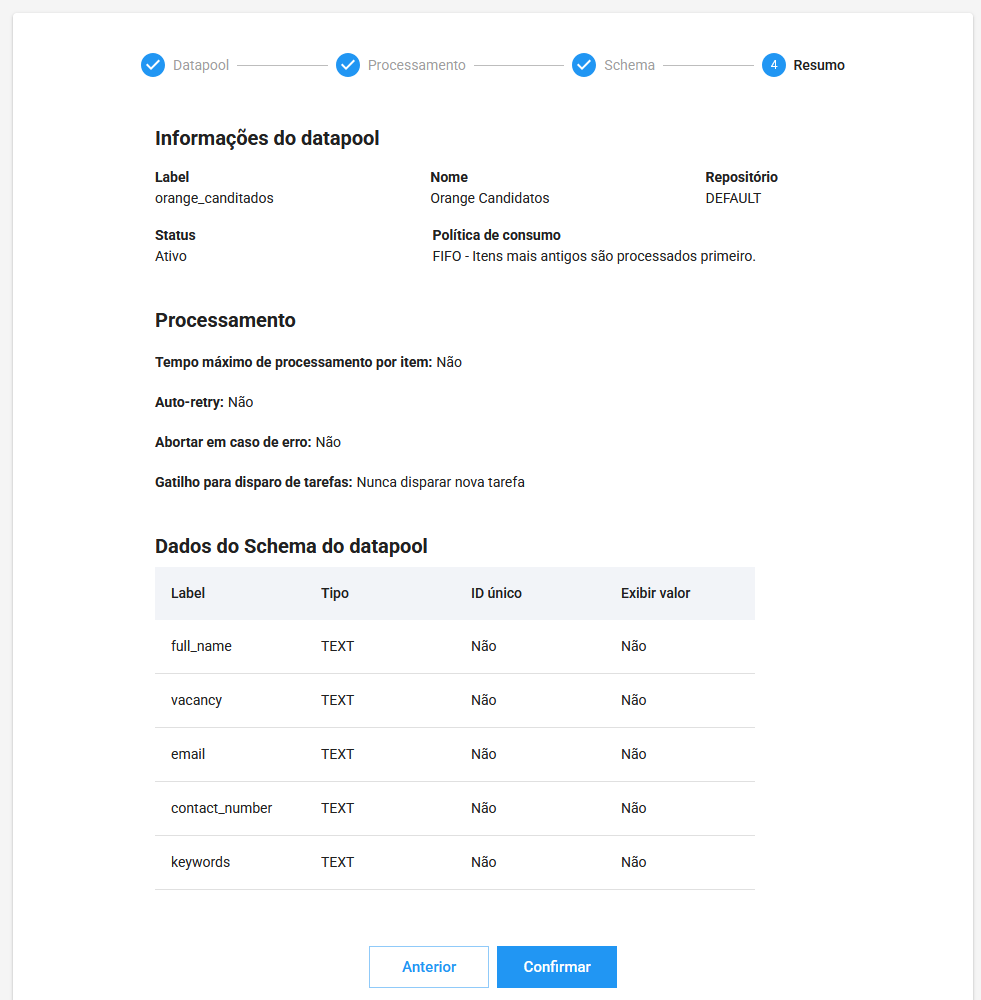
Adicionar itens ao Datapool
Após criar o Datapool, clique nele para verificar os detalhes. A tela será semelhante a essa:
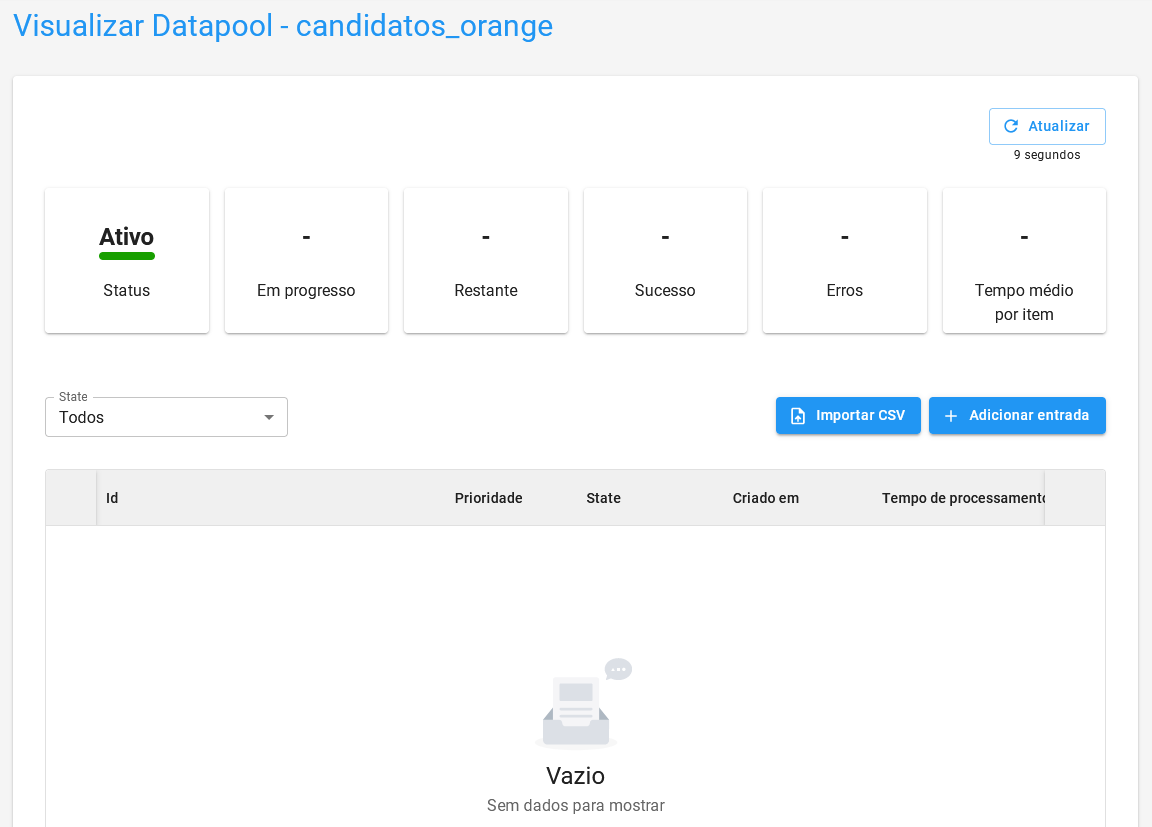
A partir desse ponto, adicione os itens de várias formas.
Adicionar manualmente
Para adicionar manualmente, clique em + Adicionar entrada, depois em + Adicionar, informando o label, o value e também a prioridade de um item.
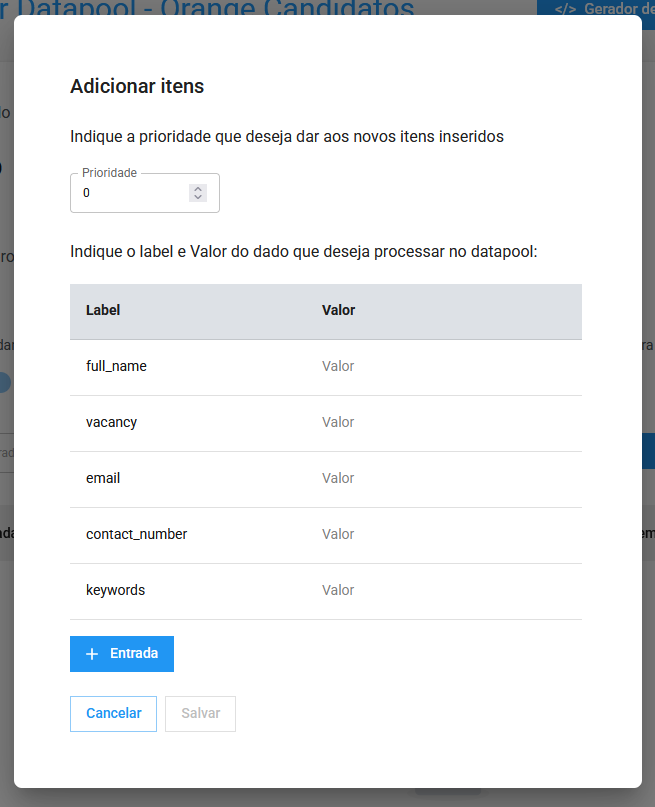
Dessa forma, cada item é adicionado individualmente. Esse processo pode ser demorado e causar erros de digitação, principalmente por ter que definir todas as colunas e valores.
Adicionar em lote
Uma forma mais eficiente de adicionar itens é por um arquivo .csv. Para isso, clique em Importar CSV e arraste o arquivo ou clique para selecionar.
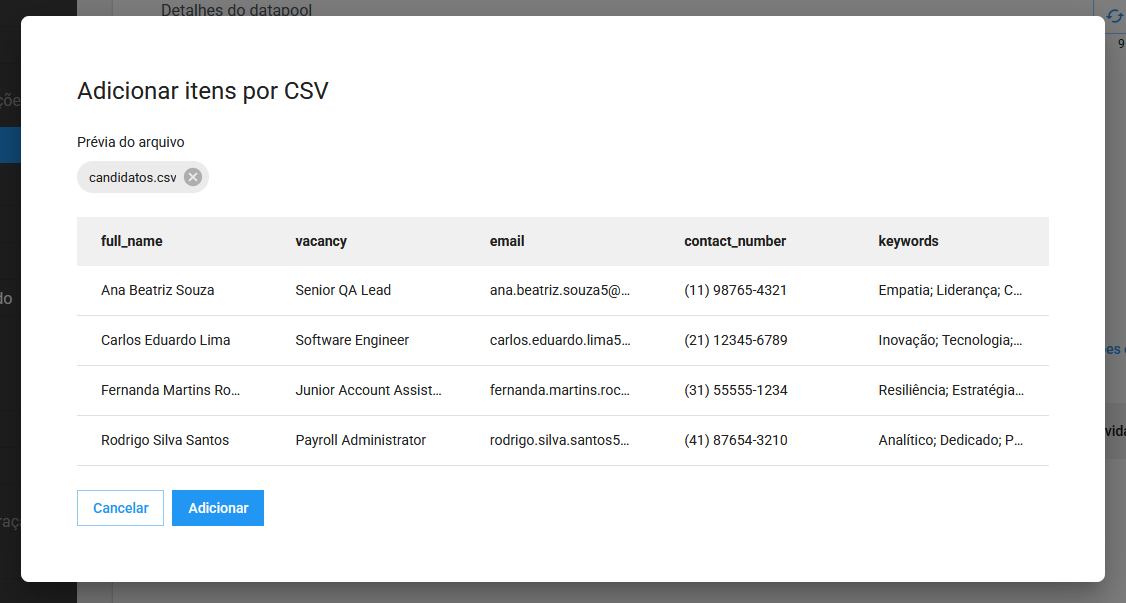
Assim, a primeira linha é considerada o cabeçalho, que define as colunas e as demais linhas se tornam os itens.
Nota
O arquivo CSV utilizado neste exemplo está disponível para download clicando nesse link.
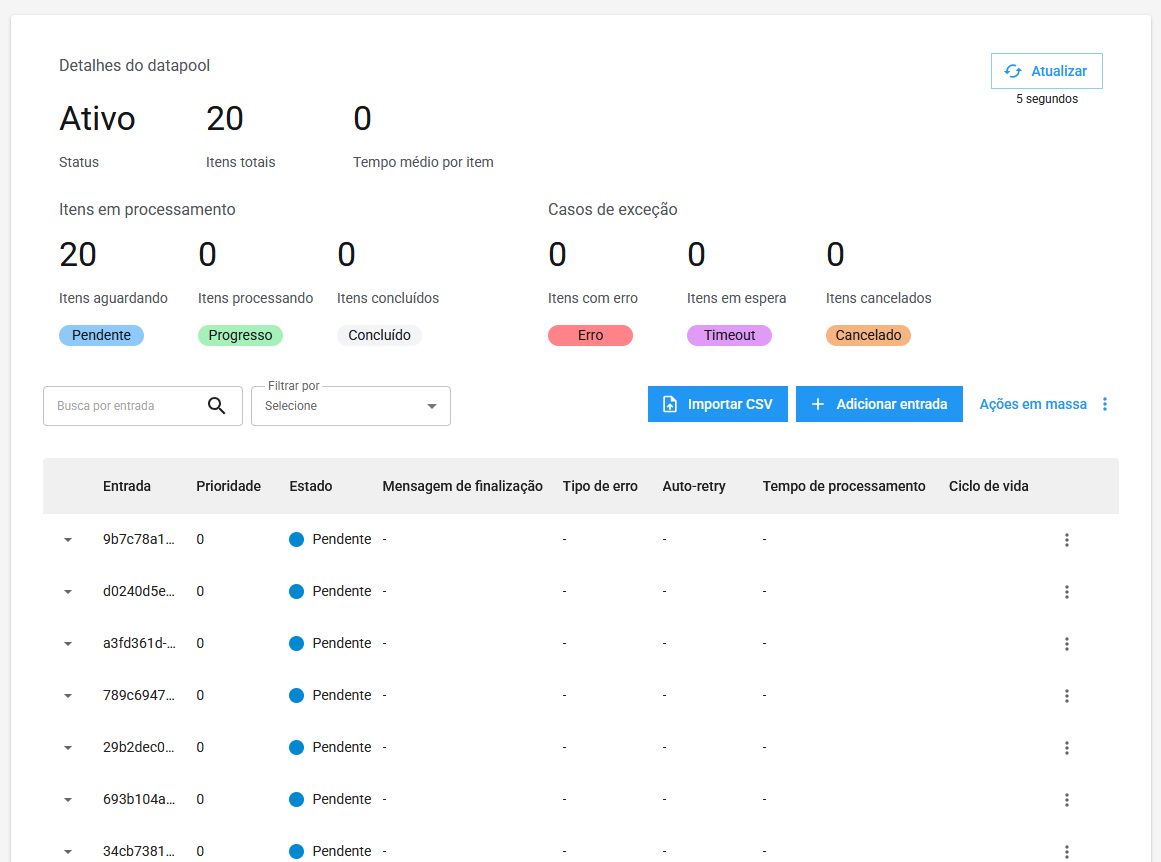
Note que os itens adicionados possuem o status PENDENTE, isso significa que estão aguardando processamento.
Nota
Para entender mais sobre os status durante o processo, veja a documentação do Datapool.
Processar os itens
Com os itens prontos para serem processados, faça uma alteração no código da automação, informando o label do Datapool criado na seguinte linha:
# Definir o datapool
datapool = maestro.get_datapool(label="orange_candidatos")